L’efficacia dei Mixing Mode e delle Sampling Frames

Background e domande della ricerca
Oggigiorno vengono utilizzati approcci in modalità mista per affrontare il problema di non copertura e l’errore di non risposta nei sondaggi su campione. In letteratura ci sono molti esempi di sondaggi che combinano modalità web, telefono e F2F, adottando progetti concorrenti o sequenziali in studi sperimentali o non sperimentali.
Le questioni di interesse sono varie, ad es. esperimenti sul formato delle domande, differenze in termini di risposta e copertura, pregiudizi sulla desiderabilità sociale e stime della qualità dei dati. Inoltre, gli studi spesso utilizzano lo stesso schema di campionamento per il rilevamento in modalità mista e mostrano risultati contrastanti sulle differenze tra i campioni.
In questo contesto, attingendo al nostro lavoro precedente (Bartoli, Respi e Fornea, 2018), applichiamo un design di sondaggio in modalità mista a diversi frame di campionamento (elenco dei telefoni fissi e pannello online). Il problema con la copertura telefonica è aggravato dal fatto che le famiglie con rete fissa non sono ugualmente rappresentate in tutta la popolazione italiana. Noi ipotizziamo che questa fonte di bias, combinata con l’errore di mancata risposta, potrebbe essere ridotta adottando approcci che utilizzano diversi frame di campionamento.
Questa ricerca ha lo scopo di valutare la rappresentatività dei campioni di un disegno di sondaggio in modalità mista (web-landline) e un sondaggio telefonico che chiama numeri di telefono fissi e mobili, confrontando le loro stime con i valori osservati dai registri degli elettori registrati e con le caratteristiche socio-economiche della popolazione italiana.
Metodo
Per valutare la rappresentatività dei campioni, per prima cosa confrontiamo il comportamento di voto stimato dai due disegni di indagine ai comportamenti di voto osservati (valori “veri”) nelle ultime elezioni politiche.
Eseguiamo analisi bivariate e utilizziamo l’errore assoluto medio, l’errore assoluto più grande e le differenze in punti percentuali, come metriche di accuratezza.
Inoltre, confrontiamo anche lo stato occupazionale e la formazione dei nostri intervistati con quelli degli intervistati in Labour Force Survey, calcolando (come metrica di accuratezza) l’errore percentuale per la categoria modale del benchmark.
Dati
Noi utilizziamo i dati provenienti da 6 sondaggi telefonici e web condotte in Italia (periodo marzo 2018 – Gennaio 2019) su telefoni fissi o proprietari di telefoni cellulari e sui membri di Opinione.net, panel online italiano.
Abbiamo progettato un sondaggio sequenziale in modalità mista (una intervista Web assistita dal computer – sondaggio CAWI seguito da un’intervista telefonica assistita dal computer – sondaggio CATI, utilizzando due diversi frame di campionamento) e un sondaggio con due diversi frame di campionamento (intervista al telefono cellulare assistita dal computer – Indagine CAMI seguita da un’indagine CATI).
Lo stesso istituto di ricerca ha commissionato tutte le indagini a Demetra opinioni.net S.r.l., che ha diviso in parti uguali ogni campione (circa 1.000 panelist / intervistati) tra i due progetti di indagine: metà degli intervistati rispetto al design in modalità mista e metà dell’indagine telefonica.
Campionamento
Entrambi i progetti adottano un campionamento delle quote: le quote sono state definite proporzionali al genere, l’età e l’area geografica delle distribuzioni di residenza della popolazione italiana (abbiamo utilizzato i dati amministrativi dal sito di dati.istat come punto di riferimento). I questionari utilizzati per ogni sondaggio sono diversi, ma riguardano tutti gli atteggiamenti e il comportamento politico, e includono una domanda con la stessa domanda di parole sul voto nelle ultime elezioni nazionali (cioè “Nelle elezioni nazionali del 4 marzo 2018, quale partito ha fatto voti per? “), che abbiamo usato nelle nostre analisi.
Nel nostro precedente lavoro (Bartoli, Respi e Fornea, 2018) abbiamo usato una domanda sulla votazione presa nel 2014, mentre in questo studio ci concentriamo sulla votazione del 2018. Le nostre indagini sono state condotte nei mesi immediatamente successivi alle elezioni politiche. Si ipotizza che “l’effetto memoria” non si sia verificato, rimuovendo così una potenziale fonte di pregiudizio dalle stime del comportamento di voto.
Tabella 1. Panoramica dei due disegni di studio
| Mode | CAWI+CATI | CAMI+CATI |
| Disegno | sequenziale | sequenziale |
| Sampling frame | panel online + elenco telefoni fissi | sconosciuto(RDD) + elenco dei telefoni fissi |
| Sampling method | quote (proporzionali al genere, l’età e l’area geografica delle distribuzioni di residenza) | quote (proporzionali al genere, l’età e l’area geografica delle distribuzioni di residenza) |
Tabella 2. Panoramica dei sondaggi
| Marzo 2018 | CATI CAWI CAMI-CATI | 6.823 6 20.506 | 371 386 757 | 5 66 4 |
| Aprile 2018 | CATI CAWI CAMI-CATI | 4.778 4 16.444 | 250 255 503 | 5 57 3 |
| Maggio 2018 | CATI CAWI CAMI-CATI | 11.186 3 13.230 | 250 252 505 | 2 75 4 |
| Settembre 2018 | CATI CAWI CAMI-CATI | 4.169 5 14.633 | 231 274 501 | 5 52 3 |
| Dicembre 2018 | CATI CAWI CAMI-CATI | 12.218 5 16.356 | 318 306 615 | 3 68 4 |
| Gennaio 2019 | CATI CAWI CAMI-CATI | 9.749 4 26.090 | 249 252 503 | 2 65 2 |
Utilizziamo anche dati secondari come benchmark:
il database degli elettori registrati (2018),
e la Labor Force Survey (2017).
Risultati: rappresentatività del comportamento di voto
I risultati delle analisi sull’entità del bias nelle stime del comportamento di voto mostrano alcune differenze tra i modelli CAMI – CATI e CAWI – CATI.
In particolare, la Tabella 3 si concentra sull’errore assoluto medio e mostra che il design CAWI – CATI ha prestazioni migliori di CAMI – CATI in tutti i sei sondaggi, quando si rappresenta il comportamento di voto.
Tabella 3. Errore assoluto medio per la domanda sul comportamento di voto di ogni campione di indagine
| | CAMI-CATI | CAWI-CATI |
| Marzo 2018 | 3,75 | 3,48 |
| Aprile 2018 | 4,42 | 3,93 |
| Maggio 2018 | 3,04 | 1,81 |
| Settembre 2018 | 2,95 | 2,78 |
| Dicambre 2018 | 4,84 | 3,31 |
| Gennaio 2019 | 3,52 | 3,48 |
Quindi, ci concentriamo sulla categoria della domanda sul comportamento di voto con il più grande errore assoluto per ogni campione di sondaggio. La Tabella 4 riporta i risultati.
Tabella 4. Massimo errore assoluto per ogni campione di sondaggio.
| | CATI-CAMI | CATI-CAWI |
| Marzo 2018 | -7,3 | -5,8 |
| Aprile 2018 | 10,6 | 8,9 |
| Maggio 2018 | 8,7 | 3,8 |
| Settembre 2018 | -6,2 | -7 |
| Dicembre 2018 | 12,7 | -7,6 |
| Gennaio 2019 | 9,3 | -8,5 |
Tre risultati principali si distinguono:
- i valori dell’errore assoluto più grande sono minori per CAWI-CATI che per il modello di indagine CAMI-CATI;
- i campioni CAMI-CATI tendono a sovrastimare sistematicamente le persone che votano “Partito Democratico”;
- i campioni CAWI-CATI tendono a rappresentare in modo sistematico le persone che votano “Forza Italia”.
Infine, esaminando le differenze percentuali per le parti principali (grafici 1-4), troviamo alcuni modelli.
Grafico 1. Differenze in punti percentuali per il ‘Partito Democratico’.
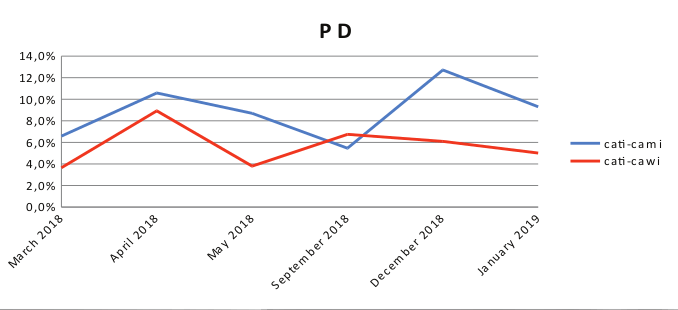
Il “Partito Democratico” è sempre sovra-rappresentato. Le differenze sono sistematicamente più elevate per CAMI-CATI che per il modello di indagine CAWI-CATI, ad eccezione dell’indagine “settembre 2018” in cui il campione CAMI – CATI offre prestazioni migliori rispetto a CAWI-CATI. L’andamento dell’indagine telefonica mostra una variabilità maggiore rispetto alle serie di sondaggi in modalità mista.
Grafico 2. Differenze di punti percentuali per “Forza Italia”.
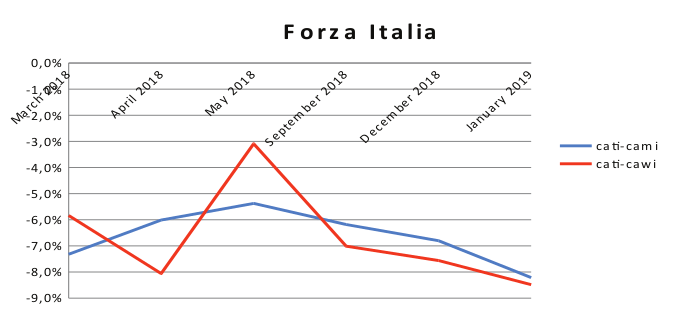
Il partito ‘Forza Italia’ è sempre sottorappresentato in entrambi i disegni di indagine. Quattro su sei campioni CAWI-CATI hanno un bias maggiore rispetto a quelli telefonici.
Grafico 3. Differenze di punti percentuali per “Lega Nord”.
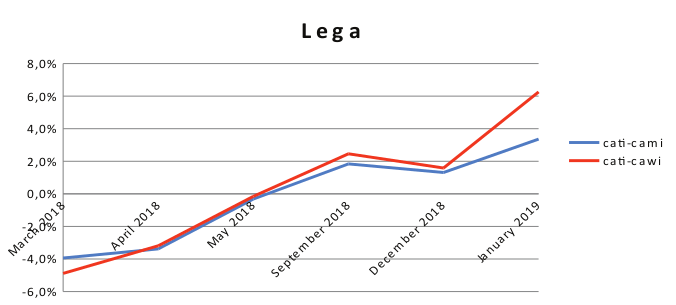
Il partito “Lega Nord” mostra uno schema interessante per entrambi i progetti di sondaggi: gli elettori della “Lega Nord” sono sottorappresentati nei primi tre sondaggi, mentre, da settembre 2018, sono sempre sovrarappresentati. Complessivamente, le differenze percentuali sono aumentate sistematicamente per entrambi i progetti di indagine da marzo 2018 a gennaio 2019.
Grafico 4. Differenze tra punti percentuali per “Movimento 5 Stelle”.
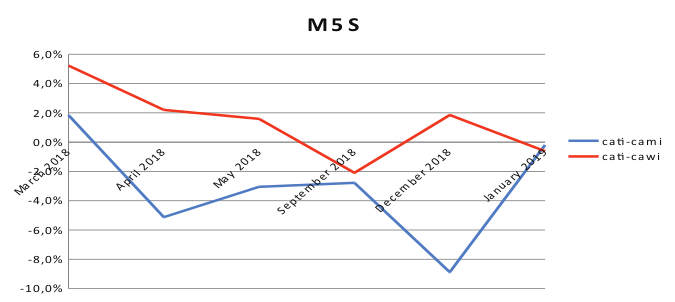
Il partito ‘Movimento 5 Stelle’ non mostra uno schema chiaro durante i sondaggi. Possiamo dire che gli intervistati di CAWI-CATI hanno più probabilità di essere gli elettori di “Movimento 5 Stelle” (fatta eccezione per l’indagine condotta a settembre 2018) rispetto agli intervistati di CAMI-CATI. Tuttavia, l’indagine più recente (vale a dire gennaio 2019) riporta valori molto bassi (e uguali) delle differenze in punti percentuali sia per i campioni in modalità mista che per quelli telefonici.
Risultati: rappresentanza delle caratteristiche socio-demografiche
L’analisi delle distorsioni nelle stime delle caratteristiche socio-economiche dei nostri campioni di indagine riporta valori elevati sia per i disegni dell’indagine CAWI-CATI che per quelli CAMI-CATI. I grafici 5 e 6 mostrano l’errore in punti percentuali per le categorie modali dello stato di occupazione (cioè persone inattive) e istruzione (cioè istruzione secondaria inferiore). Il grafico 5 mostra la percentuale di CAMI-CATI contro CAWI-CATI.
Grafico 5. Errore percentuale per persone inattive.
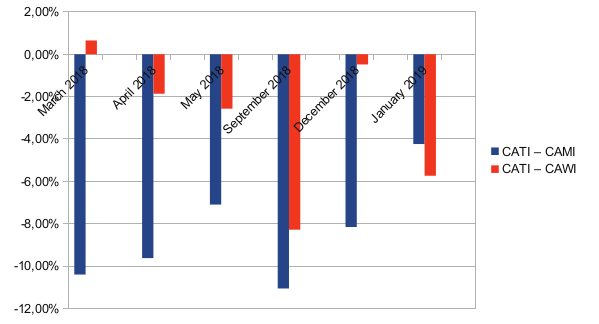
I campioni CAMI-CATI sottorappresentano sistematicamente le persone inattive (grafico 5). Il design dell’indagine CAWI-CATI offre prestazioni migliori nella rappresentazione di questa categoria. In effetti, rispetto alla serie telefonica, l’entità dell’errore è sempre minore, ad eccezione dell’ultima indagine effettuata a gennaio 2019.
Grafico 6. Errore percentuale per l’educazione secondaria inferiore.
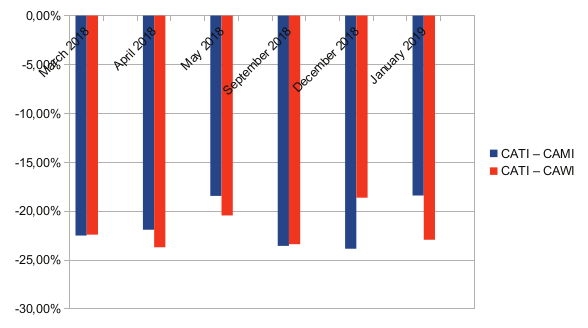
Il grafico 6 mostra che entrambi i campioni di sondaggi telefonici e in modalità mista non sono rappresentativi di persone che non hanno superato l’istruzione secondaria inferiore: tutti i campioni sottorappresentano questa categoria e le differenze con la popolazione generale sono molto marcate (almeno -18 punti percentuali).
Conclusioni
Abbiamo confrontato le stime di sei sondaggi telefonici e in modalità mista con dati di riferimento e abbiamo valutato la rappresentatività del campione. Abbiamo focalizzato le nostre analisi sul comportamento di voto, sullo stato occupazionale e sulla formazione dei rispondenti. I risultati sono coerenti con quelli del nostro precedente lavoro (Bartoli, Respi e Fornea, 2018) e mostrano che il mixaggio di entrambe le modalità e il frame di campionamento, come nel sondaggio CAWI-CATI, è una strategia più efficace nel ridurre gli errori di selezione. In particolare, si evidenziano i seguenti risultati principali.
- Il design del sondaggio CAWI-CATI si comporta meglio di quello CAMI-CATI nel rappresentare il comportamento di voto complessivo:
- a) il valore dell’errore assoluto medio è inferiore in tutti i sondaggi;
- b) la magnitudo dell’errore assoluto più grande è minore in tutte le indagini.
- Guardando le parti selezionate dagli intervistati, abbiamo identificato quattro modelli principali:
- a) i campioni CAMI-CATI tendono a sovrastimare sistematicamente le persone che votano “partito democratico”;
- b) i campioni CAMI-CATI sottorappresentano le persone che votano “Movimento 5 Stelle”;
- c) sia i campioni CAMI-CATI che CAWI-CATI sottorappresentano le persone che votano “Forza Italia”;
- d) non ci sono differenze tra i due disegni di indagine quando si rappresentano persone che votano “Lega Nord”, ma tutte le differenze sono aumentate nel tempo.
- Il design dell’indagine CAWI-CATI si comporta meglio di quello CAMI-CATI nel rappresentare lo stato occupazionale della popolazione italiana. In effetti, l’entità dell’errore percentuale per le persone inattive è sempre minore, tranne che nell’ultimo rilevamento.
- Entrambi i disegni di indagine CAWI-CATI e CAMI-CATI finiscono per non rappresentare persone che non hanno superato l’istruzione secondaria inferiore.
Leggi anche il poster dell’indagine: Poster
Autori:
Dr.ssa Chiara Respi, Università Milano-Bicocca, Italia
Dr.ssa Beatrice Bartoli, Dr Marco Fornea, Demetra opinioni.net S.r.l.